The evolution of database technology has brought forth the serverless database, a paradigm shift promising enhanced efficiency and scalability. This innovative approach decouples database management from the underlying infrastructure, offering a ‘pay-as-you-go’ model that optimizes resource allocation. Serverless databases represent a natural progression from the broader serverless computing movement, transforming how data is stored, accessed, and managed. This exploration will dissect the core principles of serverless databases, providing a comprehensive understanding of their operational characteristics, advantages, and real-world applications.
From automatic scaling and high availability to cost-efficiency and simplified management, the characteristics of serverless databases are reshaping the landscape of data management. By examining the specific features, provider offerings, and practical use cases, this analysis will equip readers with the knowledge necessary to evaluate and leverage the power of serverless databases in diverse scenarios. We will delve into the migration strategies, data models, and security aspects, offering a complete picture of the serverless database ecosystem.
Introduction to Serverless Databases
Serverless databases represent a significant paradigm shift in database management, offering a more flexible and cost-effective approach compared to traditional database systems. They abstract away the complexities of server management, allowing developers to focus on building applications rather than infrastructure. This evolution is driven by the need for scalability, efficiency, and reduced operational overhead in modern software development.
Core Concept of Serverless Databases
The fundamental principle of a serverless database is that the database provider manages the underlying infrastructure, including servers, operating systems, and scaling. This means users do not need to provision, configure, or maintain servers. The database automatically scales resources up or down based on demand, handling the complexities of capacity planning and resource allocation. This ‘pay-as-you-go’ model is a key characteristic.
Users are charged only for the actual resources consumed, such as compute time, storage, and network bandwidth. This contrasts sharply with traditional database systems, where users often pay for provisioned resources regardless of actual utilization.
Brief History of Serverless Computing and its Evolution into Databases
The concept of serverless computing emerged from the broader cloud computing landscape. Initially, cloud providers offered Infrastructure-as-a-Service (IaaS), which allowed users to rent virtual machines. Platform-as-a-Service (PaaS) followed, providing a higher level of abstraction with pre-configured environments. Serverless computing, also known as Function-as-a-Service (FaaS), represents the next evolution. FaaS enables developers to execute code without managing servers, triggering functions in response to events.The evolution of serverless databases followed a similar trajectory.
Early database offerings in the cloud required users to provision and manage virtual machines or database instances. As serverless computing matured, database providers began to offer serverless database solutions. These solutions abstracted away the server management aspects, allowing users to focus on database design and application development. This transition was driven by the demand for greater agility, scalability, and cost efficiency.
The adoption rate increased as more and more companies sought to optimize their IT spending and reduce operational burdens.
Benefits of Using a Serverless Database Over Traditional Database Systems
Serverless databases offer several advantages over traditional database systems. These benefits contribute to their growing popularity and suitability for various applications.
- Cost Efficiency: The ‘pay-as-you-go’ model of serverless databases can lead to significant cost savings, particularly for applications with fluctuating workloads. Users only pay for the resources they consume, eliminating the need to over-provision resources to handle peak loads. This is in stark contrast to traditional systems where resources are provisioned based on peak capacity. For example, a retail website that experiences heavy traffic during holiday sales would pay only for the resources used during those peak periods.
- Scalability and Elasticity: Serverless databases automatically scale resources up or down based on demand. This dynamic scaling ensures that applications can handle fluctuating workloads without manual intervention. This is achieved through automated processes within the database provider’s infrastructure. This automatic scaling eliminates the need for manual capacity planning and provisioning, reducing the risk of performance bottlenecks or wasted resources.
- Reduced Operational Overhead: Serverless databases eliminate the need for server management, including tasks such as patching, backups, and monitoring. The database provider handles these operational responsibilities, freeing up developers and database administrators to focus on application development and database design. This reduced overhead can significantly improve developer productivity and reduce operational costs.
- High Availability and Fault Tolerance: Serverless databases are designed with high availability and fault tolerance in mind. They typically employ replication, automatic failover, and other mechanisms to ensure data durability and availability. This built-in resilience reduces the risk of data loss and application downtime.
- Improved Developer Productivity: By abstracting away the complexities of server management, serverless databases allow developers to focus on writing code and building applications. This can lead to faster development cycles and improved time-to-market.
Characteristics
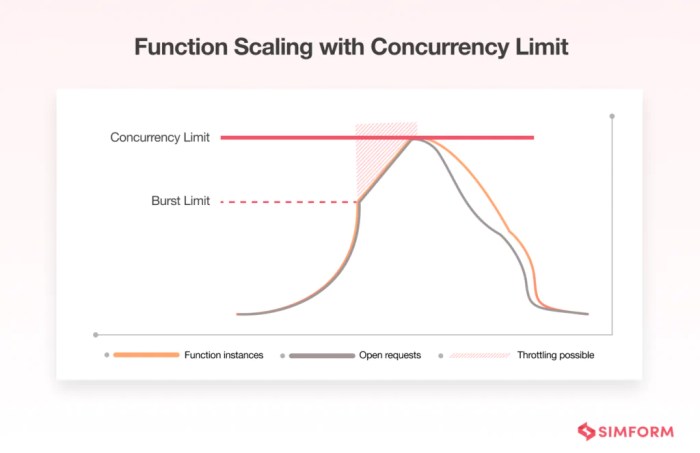
Serverless databases are distinguished by a set of key characteristics that differentiate them from traditional database systems. These features are designed to provide enhanced scalability, reduced operational overhead, and cost optimization. One of the most significant of these characteristics is automatic scaling, which allows serverless databases to dynamically adjust resources to meet fluctuating demands.
Automatic Scaling
Serverless databases dynamically adjust their resource allocation based on the incoming workload. This capability is a core feature that distinguishes them from traditional, provisioned database systems. The system automatically provisions and deprovisions resources, such as compute power and storage, to match the current demand. This automated process minimizes the need for manual intervention and allows the database to handle sudden spikes in traffic or periods of low activity efficiently.Scaling in the context of serverless databases can be categorized into two primary methods: scaling up (vertical scaling) and scaling out (horizontal scaling).
Each approach addresses different aspects of resource management and performance optimization.* Scaling Up (Vertical Scaling): This involves increasing the resources of a single instance, such as adding more CPU or memory to a database server. In a serverless context, this can mean allocating more compute units or increasing the available memory for the database engine.
Scaling Out (Horizontal Scaling)
This approach involves adding more instances of the database service to distribute the workload across multiple servers. Serverless databases typically leverage horizontal scaling to handle increased traffic. This can involve automatically creating and managing replicas or shards of the database to ensure optimal performance.The choice between scaling up and scaling out depends on the specific requirements of the workload and the architecture of the serverless database.
Serverless databases often employ a combination of both approaches, automatically adjusting resources as needed.To illustrate the differences in scaling behavior, consider a comparison table:
| Feature | Serverless Database | Traditional Database | Description |
|---|---|---|---|
| Scaling Type | Automatic (Up and Out) | Manual (Typically Up) | Serverless databases automatically scale resources based on demand, while traditional databases require manual configuration and scaling by database administrators. |
| Resource Allocation | Dynamic (Pay-per-use) | Static (Provisioned) | Serverless databases allocate resources on-demand, only charging for the actual resources consumed. Traditional databases require provisioning resources in advance, often leading to over-provisioning and wasted resources. |
| Capacity Planning | Minimal | Significant | With serverless databases, capacity planning is largely handled automatically by the platform. Traditional databases require careful planning to estimate resource needs and avoid performance bottlenecks. |
| Performance Impact | Potentially seamless scaling, minimal downtime | Can involve downtime and performance degradation during scaling operations | Serverless databases can often scale without significant downtime or performance degradation, whereas scaling traditional databases can require application downtime and manual intervention. |
Characteristics
Serverless databases, by their inherent design, prioritize resilience and uptime, ensuring data remains accessible and consistent even in the face of failures. This is achieved through a combination of architectural choices and operational strategies, all aimed at minimizing the impact of potential disruptions. The following sections will delve into the specific mechanisms serverless databases employ to guarantee high availability and fault tolerance.
High Availability and Fault Tolerance
High availability (HA) and fault tolerance are crucial characteristics of serverless databases. HA ensures the database remains operational with minimal downtime, while fault tolerance allows the system to continue functioning even if components fail. Serverless databases are engineered to achieve these goals through automated replication, distributed architectures, and self-healing capabilities.The cornerstone of HA and fault tolerance in serverless databases is data replication.
This involves creating multiple copies of the data and distributing them across different physical locations or availability zones. This redundancy mitigates the risk of data loss and ensures that if one replica becomes unavailable, another can seamlessly take over.
- Data Replication Mechanisms: Serverless databases employ various replication strategies. These strategies typically involve asynchronous or synchronous replication, depending on the consistency requirements. Asynchronous replication offers lower latency for write operations but might introduce potential eventual consistency issues. Synchronous replication ensures strong consistency by requiring all replicas to acknowledge a write before it’s considered committed, which may increase write latency. The choice of replication method is often a configurable option, allowing users to balance performance and consistency based on their application’s needs.
- Distributed Architecture: Serverless databases are built on a distributed architecture, meaning the database components are spread across multiple servers, often in different geographic regions or availability zones. This distribution inherently provides fault tolerance. If a server or an entire data center fails, the database can continue operating by utilizing the replicas located elsewhere. The architecture is designed to automatically detect and handle failures, redirecting traffic to healthy replicas.
- Self-Healing Capabilities: Serverless databases incorporate self-healing mechanisms to automatically recover from failures. These mechanisms include automated failover, which swiftly promotes a replica to become the primary database in case of a primary failure. They also involve automatic scaling to replace failed resources and ensure that the system maintains sufficient capacity. In addition, monitoring systems constantly check the health of the database components and trigger recovery actions when issues are detected.
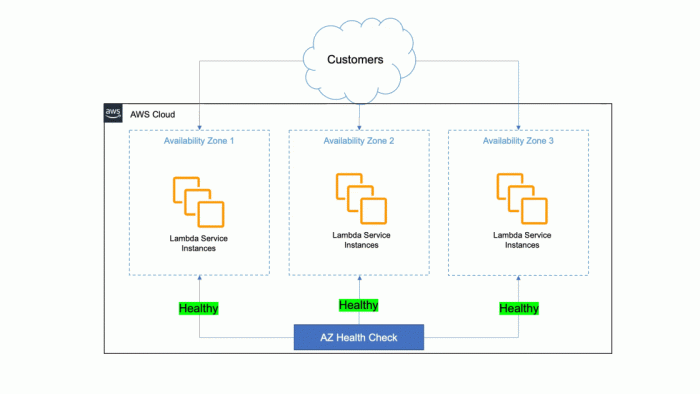
To illustrate the data replication process, consider the following diagrammatic representation:
Diagram: Data Replication Process
The diagram illustrates a simplified data replication process within a serverless database, composed of three availability zones (AZ1, AZ2, AZ3) within a single region. Each AZ contains a replica of the database.
- Data Write: A client initiates a write operation (e.g., inserting a new record). The write request is received by the primary database instance in AZ1.
- Replication to Replicas: The primary database instance in AZ1 replicates the data to the replica instances in AZ2 and AZ3. The replication method (synchronous or asynchronous) determines the timing and consistency guarantees.
- Acknowledgement (Synchronous): In a synchronous replication scenario, the primary database in AZ1 waits for acknowledgements from the replicas in AZ2 and AZ3 confirming the successful replication before considering the write operation committed.
- Read Operations: Read requests can be directed to any of the replicas. This allows for horizontal scaling and improved read performance, as the read load is distributed across multiple instances.
- Failover (Illustrative): If the primary database instance in AZ1 fails, the system automatically promotes one of the replicas (e.g., in AZ2) to become the new primary instance. The database service redirects all write and read traffic to the new primary.
This diagram is a simplified model. Real-world serverless database implementations may have more complex architectures, including multiple regions, sophisticated data sharding, and more granular replication strategies. However, the fundamental principle remains the same: data is replicated across multiple instances to ensure availability and fault tolerance.
Characteristics
Serverless databases, as discussed, offer several compelling advantages over traditional database systems. One of the most significant of these is cost efficiency. This stems from the fundamental architectural differences, primarily the removal of the need to provision and manage underlying infrastructure.
Cost Efficiency
The cost-saving advantages of serverless databases are multifaceted, primarily revolving around a “pay-as-you-go” pricing model. This model eliminates the need to pay for idle resources, a common occurrence with traditional database setups. This leads to significant cost reductions, particularly for applications with fluctuating workloads or those that experience periods of low activity.
- Elimination of Infrastructure Costs: Traditional databases require upfront investment in hardware, including servers, storage, and networking equipment. Serverless databases eliminate these capital expenditures. The provider handles all infrastructure management.
- Reduced Operational Costs: Managing traditional databases involves ongoing operational costs, including system administration, patching, backups, and security updates. Serverless databases automate many of these tasks, significantly reducing the need for dedicated database administrators and related personnel costs.
- Pay-Per-Use Pricing: Serverless databases typically employ a pay-per-use pricing model, where users are charged only for the actual resources consumed. This includes storage, compute time, and the number of requests. This contrasts sharply with traditional models, where users often pay for provisioned capacity, regardless of actual usage.
- Scalability and Optimization: Serverless databases automatically scale resources based on demand. This eliminates the need to over-provision resources to handle peak loads, a common practice in traditional systems. Furthermore, serverless providers often optimize the underlying infrastructure for efficiency, leading to further cost savings.
Pricing models vary across different serverless database providers. These models are generally designed to be transparent and predictable.
- Amazon DynamoDB: DynamoDB’s pricing is based on provisioned read/write capacity units (RCUs/WCUs), storage, and data transfer. It also offers an on-demand capacity mode, where users pay only for the reads and writes they perform, making it suitable for unpredictable workloads. Pricing is calculated based on the number of requests, data transfer, and storage consumed.
- Google Cloud Firestore: Firestore’s pricing is based on the number of reads, writes, deletes, and storage consumed. It also charges for network egress (data transfer out of the region). Firestore uses a tiered pricing model where the cost per operation decreases as the volume increases.
- Azure Cosmos DB: Cosmos DB’s pricing is based on provisioned throughput (measured in Request Units or RUs), storage, and data transfer. Users can choose to provision capacity manually or use auto-scaling. Cosmos DB offers a variety of pricing tiers and discounts for reserved capacity.
The following table provides a comparative cost analysis between serverless and traditional database systems. This comparison highlights the potential cost savings associated with serverless databases, focusing on key factors like infrastructure, maintenance, and operational costs.
| Factor | Serverless Database | Traditional Database | Notes |
|---|---|---|---|
| Infrastructure Costs | No upfront costs. Pay-per-use. | Significant upfront hardware costs (servers, storage). Ongoing maintenance and upgrade costs. | Serverless eliminates the need for hardware investment. |
| Maintenance Costs | Automated maintenance, patching, and backups. Minimal operational overhead. | Significant maintenance costs (database administrators, patching, backups, monitoring). | Serverless providers handle maintenance tasks, reducing the need for dedicated staff. |
| Operational Costs | Scales automatically. No need to over-provision. | Requires capacity planning and scaling. Potential for under-utilization and over-provisioning. | Serverless systems scale dynamically, optimizing resource utilization. |
| Pricing Model | Pay-per-request, pay-per-storage. | Subscription-based, or pay-per-capacity. | Serverless models generally lead to lower costs for applications with variable workloads. |
Characteristics
Serverless databases, by their design, significantly alter the operational landscape of database management. This paradigm shift moves away from the traditional model of manual intervention and complex infrastructure management, providing a more streamlined and automated approach. The focus shifts from managing servers and infrastructure to managing the data and application logic, leading to increased developer productivity and reduced operational overhead.
Simplified Management
Serverless databases are engineered to automate many of the tasks traditionally associated with database administration. This automation frees up database administrators (DBAs) and developers from the burden of manual operations, allowing them to focus on application development and data analysis. The simplified management approach is a core tenet of serverless architecture, offering significant advantages in terms of efficiency, scalability, and cost-effectiveness.Several tasks are either automated or completely eliminated in a serverless environment.
For example, provisioning and capacity management are handled automatically by the database provider. Scaling up or down based on demand is also automatic, ensuring optimal performance without requiring manual intervention. Updates and patching are applied seamlessly in the background, minimizing downtime and security vulnerabilities. Furthermore, backups and disaster recovery are often built-in and automated, providing data protection without the need for dedicated backup infrastructure or manual processes.Key management features of serverless databases include:
- Automatic Backups: Serverless databases typically offer automated backup capabilities. Backups are taken regularly and stored securely, often in geographically redundant locations, ensuring data durability and facilitating point-in-time recovery. For example, Amazon DynamoDB automatically creates and stores backups of your data, allowing for restoration to a specific point in time within the last 35 days.
- Automated Patching: The database provider handles all patching and version updates. This eliminates the need for DBAs to schedule and execute patches, reducing the risk of downtime and security breaches. Updates are applied in a non-disruptive manner, often during off-peak hours, ensuring minimal impact on application performance.
- Built-in Monitoring and Performance Optimization: Serverless databases provide built-in monitoring tools that offer real-time insights into database performance, resource utilization, and query execution. These tools enable developers to identify and resolve performance bottlenecks quickly. Some platforms also offer automated performance optimization features, such as query optimization and index management.
- Simplified Scaling: Serverless databases automatically scale resources based on demand. This dynamic scaling eliminates the need to manually provision or de-provision resources, ensuring optimal performance and cost efficiency. The database automatically adjusts to handle fluctuations in traffic, providing consistent performance even during peak loads.
- High Availability and Disaster Recovery: Serverless databases are designed with high availability and disaster recovery in mind. Data is typically replicated across multiple availability zones or regions, ensuring that the database remains accessible even in the event of a hardware failure or regional outage. Failover mechanisms are automated, minimizing downtime and data loss.
- Simplified Security Management: Serverless databases often provide built-in security features, such as encryption at rest and in transit, access control mechanisms, and integration with identity and access management (IAM) services. These features simplify security management and reduce the risk of data breaches. For instance, Google Cloud’s Cloud SQL offers encryption for data at rest and in transit by default.
Characteristics

Serverless databases, by their nature, introduce a paradigm shift in how data security is approached. The cloud provider assumes much of the responsibility for underlying infrastructure security, allowing developers to focus on application-level security. However, this doesn’t absolve the user of all security responsibilities. Understanding and leveraging the security features offered by serverless databases is crucial for protecting sensitive data.
Security Features
Serverless databases offer a variety of built-in security features designed to protect data at rest and in transit, and to control access. These features are often managed and configured through the cloud provider’s console or API, providing a centralized point of control. The specific features and their implementation can vary between different database services, but common offerings include encryption, access control, network security, and auditing.
Encryption Methods
Encryption is a fundamental aspect of securing data in serverless databases. It ensures that even if data is accessed without authorization, it remains unreadable. Encryption is typically applied at two primary stages: at rest and in transit.* Encryption at Rest: This protects data stored on the database servers. The cloud provider typically handles the encryption keys, either managing them on behalf of the user or providing options for user-managed keys.
Common encryption algorithms used include:
Advanced Encryption Standard (AES)
AES is a symmetric block cipher widely adopted for its speed and security. AES-256, using a 256-bit key, is a common choice for strong encryption.
Key Management Service (KMS) Integration
Serverless databases often integrate with KMS to allow users to manage their encryption keys. This provides greater control over key rotation, key policies, and audit trails.
Encryption in Transit
This protects data as it travels between the client and the database server. Encryption in transit is typically implemented using Transport Layer Security (TLS), which provides a secure channel for communication. TLS uses a combination of symmetric and asymmetric cryptography to establish a secure connection.
TLS Versions
Serverless databases typically support the latest versions of TLS (e.g., TLS 1.2 or TLS 1.3) to ensure the highest level of security. Older, less secure versions are often deprecated.
Certificate Management
The database service handles certificate management, ensuring that the certificates used for TLS encryption are valid and up-to-date.
Best Practices for Securing a Serverless Database
Securing a serverless database requires a multi-layered approach that encompasses configuration, access control, and monitoring. The following are key best practices:* Enforce Strong Authentication and Authorization: Implement robust authentication mechanisms to verify user identities and authorization policies to control access to data and resources. Use multi-factor authentication (MFA) where possible.
Utilize Encryption
Always enable encryption at rest and in transit. If possible, leverage customer-managed keys (CMK) to retain control over encryption keys.
Implement Network Security
Restrict access to the database by using network security features such as:
Virtual Private Clouds (VPCs)
Use VPCs to isolate the database from the public internet.
Firewalls
Configure firewalls to control inbound and outbound traffic.
Private Endpoints
Use private endpoints to access the database from within the VPC, avoiding exposure to the public internet.
Regularly Audit and Monitor
Implement comprehensive auditing and monitoring to track database activity, detect suspicious behavior, and ensure compliance. Review audit logs regularly for any security incidents.
Follow the Principle of Least Privilege
Grant users and applications only the minimum necessary permissions to perform their tasks. Avoid granting excessive privileges.
Keep Software Up-to-Date
Ensure that the database service and any associated client libraries or tools are up-to-date with the latest security patches and updates.
Regularly Back Up Data
Implement a robust backup and recovery strategy to protect against data loss. Test the recovery process regularly.
Protect Sensitive Data
Use techniques like data masking and tokenization to protect sensitive data. Data masking replaces sensitive data with non-sensitive equivalents, while tokenization replaces sensitive data with unique tokens.
Review and Update Security Configurations
Regularly review and update security configurations to address new threats and vulnerabilities. Stay informed about the latest security best practices and recommendations from the cloud provider.
Popular Serverless Database Providers
Serverless databases have gained significant traction in recent years, driven by the need for scalability, cost-efficiency, and reduced operational overhead. Several providers offer serverless database solutions, each with unique strengths and target use cases. This section explores some of the leading providers in this space, comparing their features and services to provide a comprehensive overview.
Leading Serverless Database Providers
The serverless database landscape is competitive, with several established cloud providers and specialized database vendors offering compelling solutions. Understanding the offerings of different providers is crucial for selecting the right database for a particular application.
- Amazon DynamoDB: A fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
- Google Cloud Firestore: A fully managed, serverless, NoSQL document database that simplifies application development. It is designed for real-time synchronization and offline support.
- Azure Cosmos DB: A globally distributed, multi-model database service that allows developers to choose from a variety of APIs, including SQL, MongoDB, Cassandra, Gremlin, and Table.
- FaunaDB: A serverless database with a GraphQL API, designed for building modern applications. It focuses on strong consistency and transactional capabilities.
- Supabase: An open-source Firebase alternative that offers a serverless database built on PostgreSQL.
Feature Comparison of Serverless Database Providers
A comparative analysis of the key features offered by these providers helps in understanding their suitability for different application requirements. The following table compares Amazon DynamoDB, Google Cloud Firestore, and Azure Cosmos DB across several key dimensions.
| Feature | Amazon DynamoDB | Google Cloud Firestore | Azure Cosmos DB |
|---|---|---|---|
| Supported Data Models | Key-value and document | Document | Multi-model (Key-value, document, graph, column family) |
| Pricing Model | Pay-per-request (Provisioned capacity and On-demand) | Pay-per-read/write/storage | Pay-per-request (Provisioned throughput and Auto-scale) |
| Integration Capabilities | Tight integration with other AWS services (Lambda, S3, etc.) | Seamless integration with Google Cloud services (Cloud Functions, App Engine, etc.) | Deep integration with Azure services (Functions, App Service, etc.) |
| Consistency | Eventually consistent by default, strong consistency available | Strong consistency (configurable) | Configurable consistency levels (Eventual, Consistent Prefix, Session, Bounded Staleness, Strong) |
The table provides a simplified comparison. Each provider offers a range of additional features and capabilities, such as global distribution, data replication, and security features. For example, DynamoDB offers automatic scaling based on traffic patterns, allowing applications to handle sudden spikes in requests without manual intervention. This is crucial for applications with unpredictable workloads. Google Cloud Firestore excels in real-time data synchronization, making it ideal for applications requiring live updates and collaborative features.
Azure Cosmos DB’s multi-model support enables developers to choose the best data model for their specific use case, offering flexibility for complex application requirements.
Use Cases for Serverless Databases
Serverless databases, due to their inherent scalability, cost-effectiveness, and operational simplicity, are finding increasing adoption across a wide array of applications and industries. Their ability to automatically manage resources based on demand makes them particularly well-suited for dynamic workloads and scenarios where resource provisioning is unpredictable. This section explores several key use cases and provides examples of industries leveraging serverless database technology.
Common Use Cases
Serverless databases excel in applications characterized by fluctuating traffic patterns, event-driven architectures, and the need for rapid development cycles. They are frequently chosen for their ability to adapt to varying workloads without requiring manual intervention.
- Web and Mobile Applications: Serverless databases are a natural fit for web and mobile applications, especially those with a global user base. Their ability to scale automatically to handle peak traffic during events like product launches or marketing campaigns ensures a consistent user experience.
- IoT (Internet of Things) Applications: IoT applications generate vast amounts of data from connected devices. Serverless databases can efficiently ingest, store, and process this data, providing insights for analytics and real-time decision-making. The pay-per-use model is especially attractive in this context, as the volume of data can vary significantly.
- Content Management Systems (CMS): CMS platforms, especially those serving dynamic content, benefit from the scalability and cost-efficiency of serverless databases. They can easily handle fluctuating traffic and content updates without requiring constant manual resource adjustments.
- E-commerce Platforms: E-commerce applications experience peak traffic during sales events and holidays. Serverless databases automatically scale to accommodate these spikes in demand, ensuring a smooth shopping experience for customers and preventing performance bottlenecks.
- Gaming Applications: Online games require highly scalable and responsive databases to manage player data, game states, and leaderboards. Serverless databases provide the necessary performance and scalability to handle a large number of concurrent users.
- Data Analytics and Reporting: Serverless databases are suitable for storing and querying large datasets for analytical purposes. Their ability to automatically scale compute resources allows for fast data processing and report generation.
Industries Adopting Serverless Databases
Several industries are actively adopting serverless database technologies to improve efficiency, reduce costs, and accelerate development cycles. The specific benefits vary depending on the industry’s requirements.
- E-commerce: E-commerce businesses use serverless databases to handle fluctuating traffic during sales and promotions, ensuring a seamless customer experience. The pay-per-use model helps to optimize infrastructure costs.
- Media and Entertainment: Media companies use serverless databases for content delivery, user data management, and real-time analytics. The ability to scale resources on demand is crucial for handling large volumes of media content and user interactions.
- Financial Services: Financial institutions are exploring serverless databases for various applications, including fraud detection, transaction processing, and regulatory compliance. The scalability and security features of serverless databases are attractive in this context.
- Healthcare: Healthcare providers are using serverless databases for managing patient data, medical records, and clinical analytics. The scalability and compliance features offered by these databases are important for handling sensitive health information.
- Gaming: Gaming companies are increasingly adopting serverless databases for managing player data, game states, and leaderboards. The ability to handle a large number of concurrent users and scale resources on demand is crucial for online gaming platforms.
- Technology: Technology companies across various sectors are adopting serverless databases for web and mobile applications, IoT projects, and data analytics. The benefits of serverless databases align with the need for rapid development, scalability, and cost optimization.
Benefits in a Web Application Scenario
Serverless databases offer significant advantages for web application development and deployment, resulting in improved performance, reduced operational overhead, and lower costs. The following blockquote provides a concise illustration of these benefits.
Consider a web application with a fluctuating user base. Traditional databases require provisioning resources based on peak expected load, leading to over-provisioning and wasted resources during periods of low traffic. A serverless database, however, automatically scales compute and storage resources based on actual demand. This ensures that the application always has the necessary resources to handle the current workload without requiring manual intervention. Developers can focus on building and deploying features rather than managing infrastructure. This leads to faster development cycles, reduced operational costs, and improved application performance. For example, during a flash sale, the serverless database will automatically scale up to accommodate the surge in traffic, ensuring that the application remains responsive and available to users. After the sale, it will automatically scale down, reducing costs.
Methods for Migrating to a Serverless Database

Migrating an existing database to a serverless platform involves choosing the right strategy to minimize downtime, data loss, and application disruption. The optimal method depends on factors such as the size and complexity of the database, the acceptable downtime window, and the existing infrastructure. This section explores several migration methods, detailing their considerations, challenges, and providing a step-by-step procedure for a sample migration.
Methods for Migrating an Existing Database
Several approaches exist for migrating a database to a serverless environment. Each method presents unique trade-offs regarding complexity, downtime, and cost.
- Lift and Shift (Rehosting): This involves migrating the database as-is to a serverless platform. This is generally the quickest method, minimizing code changes. However, it might not fully leverage the serverless platform’s capabilities, such as automatic scaling, and can be less cost-effective if the database isn’t optimized for serverless environments.
- Replatforming: This method involves making some changes to the database, such as changing the operating system or database engine, to optimize it for the serverless environment. It offers a balance between effort and benefits.
- Refactoring: This involves significantly changing the database structure and application code to fully exploit the serverless platform’s features. This approach can provide the most significant benefits in terms of scalability, cost efficiency, and performance but requires the most effort and time.
- Re-architecting: This involves redesigning the entire database and application from scratch, taking full advantage of serverless design principles. This offers the greatest potential for optimization but also the highest cost and risk.
Considerations and Challenges of Each Migration Method
Each migration method has its own set of considerations and potential challenges that need to be addressed.
- Lift and Shift: The primary challenge is ensuring compatibility between the existing database and the serverless platform. Considerations include data format compatibility, network configurations, and security settings. The existing database schema and application code might require minor adjustments. Data transfer speed and downtime are crucial considerations.
- Replatforming: This method requires a careful evaluation of database engine compatibility and performance characteristics on the serverless platform. Challenges include migrating the data, testing the new environment, and minimizing downtime. It is essential to analyze the performance impact of the changes and optimize the database accordingly.
- Refactoring: This method requires a deep understanding of the existing database schema and application code. The main challenge is the time and effort required to refactor the code and database. Testing is crucial to ensure data integrity and application functionality. A detailed migration plan and rollback strategy are essential.
- Re-architecting: This approach involves the most significant changes and carries the highest risk. Challenges include designing a new database schema, rewriting application code, and migrating data. A phased rollout strategy and thorough testing are essential to mitigate risk.
Step-by-Step Procedure for Migrating a Sample Database
A sample migration of a relational database (e.g., MySQL) to a serverless database (e.g., Amazon Aurora Serverless) will be presented, using a “lift and shift” approach as a simplified example.
- Assessment and Planning: Analyze the existing database schema, data volume, and application dependencies. Select the appropriate serverless database provider and instance type. Determine the migration strategy (e.g., “lift and shift”). Create a detailed migration plan, including timelines, roles, and responsibilities. Estimate the potential downtime.
- Environment Setup: Create a new serverless database instance on the selected platform (e.g., Aurora Serverless). Configure network settings (e.g., VPC, security groups) to allow secure access to the new database.
- Data Migration: Choose a data migration tool (e.g., AWS Database Migration Service (DMS), mysqldump). Create a backup of the existing database. Migrate the data to the new serverless database instance. Monitor the migration process for errors and performance issues. Data migration speed depends on the network, database size, and tool used.
- Application Configuration: Update the application’s connection settings to point to the new serverless database instance. Test the application thoroughly to ensure that it can connect to the new database and that all data is accessible. Address any compatibility issues between the application and the new database.
- Testing and Validation: Conduct comprehensive testing to validate the migrated data and application functionality. Perform performance testing to ensure that the new database instance meets performance requirements. Compare the performance of the old and new database instances. Implement monitoring and alerting for the new database instance.
- Cutover and Monitoring: Switch the application traffic to the new serverless database instance. Monitor the new database instance for performance, errors, and security vulnerabilities. If any issues arise, revert to the original database instance. Once the migration is complete, decommission the old database instance.
Data Models and Serverless Databases
Serverless databases, by their nature, offer flexibility in the data models they support. This adaptability is crucial for accommodating the diverse requirements of modern applications. The choice of data model significantly influences how data is structured, accessed, and managed, impacting performance, scalability, and overall efficiency. Understanding the available options and their respective strengths is paramount for selecting the most appropriate serverless database solution for a given use case.
Different Data Models Supported by Serverless Databases
Serverless databases typically support a range of data models to cater to different application needs. The most common data models include document, key-value, relational, and graph databases. The specific models supported can vary depending on the provider. Each model has unique characteristics that make it suitable for particular types of data and access patterns.
- Document Databases: Document databases store data in a flexible, semi-structured format, often using JSON-like documents. This allows for the storage of complex data structures without requiring a rigid schema. This is ideal for applications where data structures evolve frequently or where the relationships between data elements are not always well-defined upfront.
- Key-Value Databases: Key-value databases are the simplest form of NoSQL databases, storing data as key-value pairs. They excel in high-performance read and write operations, making them suitable for caching, session management, and other scenarios where quick data retrieval is critical.
- Relational Databases: Relational databases, based on the relational model, organize data into tables with predefined schemas and relationships between tables. They provide strong data consistency and support complex queries through SQL. They are well-suited for applications requiring data integrity, complex transactions, and sophisticated reporting.
- Graph Databases: Graph databases store data as nodes and edges, representing relationships between data elements. This model is optimized for traversing complex relationships and is ideal for applications such as social networks, recommendation engines, and fraud detection.
Examples of Data Model Usage in Serverless Database Implementations
The choice of data model directly influences how applications interact with the serverless database. Several examples illustrate how different data models are employed in serverless database implementations.
- Document Database Example: A content management system (CMS) using a document database like MongoDB Atlas (serverless tier) might store articles as JSON documents. Each document could contain fields like “title,” “author,” “content,” “tags,” and “publicationDate.” This flexible structure allows for easy modification of article content and the addition of new fields without schema migrations.
- Key-Value Database Example: A serverless application managing user sessions might use a key-value store like Amazon DynamoDB (serverless capacity) to store session data. The user’s session ID would serve as the key, and the associated value would contain session details such as user profile information, authentication status, and shopping cart contents. This allows for rapid retrieval of session data across different application components.
- Relational Database Example: An e-commerce platform using a serverless relational database such as Amazon Aurora Serverless might store product information, customer details, and order data in relational tables. The relationships between these tables (e.g., a customer placing an order, an order containing products) would be defined using foreign keys, ensuring data consistency and facilitating complex queries for reporting and analytics.
- Graph Database Example: A social media application using a graph database like Amazon Neptune (serverless option) could represent users as nodes and their connections (friendships, follows) as edges. This allows for efficient queries to find mutual friends, suggest connections, and analyze social network patterns. For instance, finding all the friends of friends of a particular user can be achieved with graph traversal queries.
Process of Creating a Simple Database Schema Using a Specific Data Model
The process of creating a database schema varies depending on the data model chosen and the specific serverless database provider. However, the general steps remain consistent. Let’s demonstrate the schema creation process for a simple document database using MongoDB Atlas (serverless).
- Choose a Data Model: In this case, we will use the document model, suitable for storing flexible, semi-structured data.
- Define Collections: A collection is analogous to a table in a relational database. For our example, let’s define a collection called “users” to store user information.
- Define Fields (Document Structure): Within the “users” collection, we define the fields (keys) and their data types for each document. For example:
- “firstName”: String
- “lastName”: String
- “email”: String
- “age”: Number
- “address”: “street”: String, “city”: String, “zipCode”: String
- Create Indexes (Optional): To optimize query performance, create indexes on frequently queried fields. For example, create an index on the “email” field to allow for fast lookups by email address.
- Insert Sample Data: Populate the collection with sample documents to test the schema and ensure it functions as expected.
For example:
"firstName": "John", "lastName": "Doe", "email": "[email protected]", "age": 30, "address": "street": "123 Main St", "city": "Anytown", "zipCode": "12345"
This simple schema allows for storing user information in a flexible and scalable manner. As the application evolves, the schema can be easily modified by adding or removing fields without requiring major schema migrations, a key benefit of using document databases.
Final Summary
In conclusion, serverless databases represent a significant advancement in data management, offering a flexible, scalable, and cost-effective alternative to traditional systems. Their inherent characteristics, including automatic scaling, high availability, and simplified management, address critical challenges in modern application development. The shift towards serverless databases is undeniable, and as the technology matures, its adoption will continue to accelerate, reshaping the future of data-driven applications.
Understanding the intricacies of serverless databases, from their operational features to their practical implementations, is essential for any organization aiming to stay at the forefront of technological innovation.
Quick FAQs
What are the primary advantages of using a serverless database over a traditional database?
Serverless databases offer several advantages, including automatic scaling, reduced operational overhead, cost optimization through pay-as-you-go pricing, and high availability with built-in fault tolerance. They eliminate the need for manual server provisioning and management, allowing developers to focus on application development rather than infrastructure.
How does automatic scaling work in a serverless database?
Serverless databases automatically adjust resources (compute and storage) based on real-time demand. They scale up by increasing the capacity of existing resources and scale out by adding more resources. This dynamic adjustment ensures optimal performance and cost efficiency, as resources are only provisioned when needed.
What security features are typically included in serverless databases?
Serverless databases often include features like encryption at rest and in transit, access control mechanisms (e.g., IAM roles), network isolation, and regular security audits. These features are designed to protect data confidentiality, integrity, and availability within a secure environment.
How does the cost model of a serverless database differ from a traditional database?
Serverless databases typically use a pay-as-you-go pricing model, where you only pay for the resources you consume. This contrasts with traditional databases, which often require upfront investments in infrastructure and fixed monthly costs, regardless of actual usage. Serverless databases offer greater cost efficiency, especially for applications with fluctuating workloads.
What types of data models are supported by serverless databases?
Serverless databases often support a variety of data models, including key-value, document, relational, and graph databases. The specific models supported vary by provider. This flexibility allows developers to choose the data model that best fits their application’s requirements.