The convergence of serverless computing and machine learning inference presents a paradigm shift in how we deploy and utilize predictive models. This synergy offers unprecedented opportunities for cost optimization and scalability, enabling developers to build highly responsive and efficient applications. Serverless architecture allows for on-demand resource allocation, automatically scaling to meet fluctuating demands, thereby minimizing operational overhead and maximizing resource utilization.
This approach empowers data scientists and engineers to focus on model development and innovation, rather than infrastructure management.
This guide provides a comprehensive exploration of how to leverage serverless platforms for machine learning inference. It delves into the core concepts of serverless computing, the benefits it offers for machine learning workloads, and the practical steps involved in deploying and managing inference endpoints. From choosing the right platform and preparing your models to handling data, monitoring performance, and ensuring security, this guide equips you with the knowledge and tools to build robust, scalable, and cost-effective machine learning inference solutions.
Introduction to Serverless Machine Learning Inference
Serverless machine learning inference represents a paradigm shift in how machine learning models are deployed and utilized. It combines the benefits of serverless computing with the computational demands of machine learning inference, offering a scalable and cost-effective solution for real-time predictions and insights. This approach allows developers to focus on the model itself rather than the underlying infrastructure, significantly streamlining the deployment process.Serverless machine learning inference leverages the strengths of both serverless computing and machine learning inference.
This combination provides a robust platform for deploying and managing machine learning models in production environments.
Core Concepts of Serverless Computing
Serverless computing is a cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources. Developers deploy code without managing servers, allowing for automatic scaling, high availability, and pay-per-use pricing. This approach contrasts with traditional server-based deployments, where developers are responsible for provisioning, scaling, and maintaining the underlying infrastructure.
- Automatic Scaling: Serverless platforms automatically scale resources based on demand. When a function is invoked, the platform allocates the necessary resources. This ensures optimal performance during periods of high traffic and minimizes costs during periods of low traffic. For instance, a serverless function handling image recognition can automatically scale up to handle a surge in requests during a promotional campaign.
- Pay-per-Use Pricing: Users are charged only for the actual compute time consumed by their code. This eliminates the need to pay for idle resources, making serverless a cost-effective solution for applications with variable workloads. This is particularly beneficial for machine learning inference, where the demand for predictions can fluctuate significantly.
- Event-Driven Architecture: Serverless functions are typically triggered by events, such as HTTP requests, database updates, or scheduled tasks. This event-driven architecture enables the creation of highly responsive and scalable applications. A machine learning model can be triggered by new data uploads to a cloud storage bucket, automatically generating predictions as data becomes available.
- Abstraction of Infrastructure: The cloud provider handles all infrastructure management, including server provisioning, operating system patching, and scaling. This allows developers to focus on writing code and building applications, rather than managing servers. This simplification accelerates the development and deployment process.
Overview of Machine Learning Inference
Machine learning inference is the process of using a trained machine learning model to make predictions on new, unseen data. This process is critical for deploying machine learning models in real-world applications, where the model must provide timely and accurate predictions. The performance of the inference process directly impacts the user experience and the value derived from the machine learning model.The core steps involved in machine learning inference include:
- Data Preprocessing: Preparing the input data to match the format and characteristics expected by the machine learning model. This may involve cleaning, transforming, and scaling the data. For example, if a model is trained on numerical data that is normalized, the new data must also be normalized.
- Model Loading: Loading the pre-trained machine learning model into memory. This model contains the learned parameters and weights that allow it to make predictions. The choice of model loading strategy can impact inference latency and resource consumption.
- Prediction Generation: Feeding the preprocessed input data into the loaded model to generate predictions. This involves performing the mathematical operations defined by the model’s architecture. For instance, a neural network will perform matrix multiplications and activation function calculations.
- Post-Processing: Transforming the raw model output into a user-friendly format. This may involve converting numerical predictions into labels, applying confidence thresholds, or formatting the output for display. For example, a model that predicts the probability of a product purchase might have its probability threshold set to only provide a purchase recommendation if the probability exceeds 0.7.
Benefits of Using Serverless for Machine Learning Inference
Serverless computing provides several key advantages for machine learning inference, including improved cost efficiency and enhanced scalability. These benefits make serverless an attractive option for deploying and managing machine learning models in production.
- Cost Efficiency: Serverless platforms offer pay-per-use pricing, eliminating the need to pay for idle resources. This can significantly reduce the cost of machine learning inference, especially for applications with variable workloads. For example, an image recognition service that experiences peak traffic during business hours and low traffic overnight can achieve significant cost savings by using serverless functions.
- Scalability: Serverless platforms automatically scale resources based on demand, ensuring that the inference service can handle sudden spikes in traffic without performance degradation. This scalability is crucial for applications that need to respond to unpredictable user behavior. For example, a recommendation engine can scale up to handle increased requests during a flash sale.
- Reduced Operational Overhead: Serverless platforms eliminate the need for developers to manage servers, allowing them to focus on the machine learning model itself. This reduces the operational overhead associated with deploying and maintaining the inference service. This allows for faster iteration and deployment cycles.
- Simplified Deployment: Serverless platforms simplify the deployment process, allowing developers to quickly deploy and update machine learning models. This accelerates the time-to-market for machine learning applications. For instance, an A/B testing experiment on a recommendation model can be deployed and evaluated quickly without the need for server provisioning.
Choosing the Right Serverless Platform
Selecting the appropriate serverless platform is a critical decision in deploying machine learning inference workloads. This choice significantly impacts performance, cost, scalability, and the overall development experience. The optimal platform depends on factors such as the complexity of the model, the volume of inference requests, the desired latency, and the budget constraints.
Leading Serverless Platforms
Several serverless platforms are prominent in the cloud computing landscape, each with its own strengths and weaknesses when it comes to machine learning inference. Understanding the characteristics of each platform is essential for making an informed decision.
- AWS Lambda: AWS Lambda is a widely adopted serverless compute service that allows developers to run code without provisioning or managing servers. It supports multiple programming languages, including Python, which is commonly used for machine learning. Lambda integrates seamlessly with other AWS services, such as S3 for model storage and API Gateway for API endpoints. A key advantage is its pay-per-use pricing model, which can be cost-effective for variable workloads.
However, cold starts can introduce latency, and the maximum execution time and memory limits can be restrictive for complex models.
- Azure Functions: Azure Functions is Microsoft’s serverless compute service, providing a similar functionality to AWS Lambda. It also supports various programming languages and integrates well with other Azure services. Azure Functions offers features like durable functions for stateful workflows and a rich set of triggers and bindings. Its pricing model is based on consumption, with a free tier available for low-volume usage.
Azure Functions provides excellent integration with other Azure services, which can be a significant advantage for organizations already invested in the Azure ecosystem.
- Google Cloud Functions: Google Cloud Functions is Google’s serverless offering, designed to execute code in response to events. It supports popular programming languages like Python, Node.js, and Go. Cloud Functions integrates with other Google Cloud services, such as Cloud Storage, Cloud Pub/Sub, and Cloud AI Platform. It offers a pay-per-use pricing model and is known for its fast cold start times compared to some competitors.
Google Cloud Functions is often favored for its strong integration with Google’s machine learning services and its global network of data centers.
Pricing Models for Machine Learning Inference
The pricing model is a crucial factor in selecting a serverless platform, especially for machine learning inference, where computational costs can quickly accumulate. Different platforms employ distinct approaches to charging for resource consumption.
- Pay-per-use: This is the most common pricing model for serverless platforms. You are charged only for the actual resources consumed, such as the execution time and memory usage. For example, AWS Lambda charges based on the number of requests, the duration of the request, and the amount of memory allocated. This model is advantageous for workloads with variable traffic, as it avoids paying for idle resources.
However, it requires careful monitoring and optimization to control costs.
- Consumption-based pricing: Similar to pay-per-use, consumption-based pricing charges for the resources used. Azure Functions, for instance, uses a consumption plan where you pay only for the compute power your function consumes. The cost is calculated based on the number of executions, the execution time, and the memory consumed. This model aligns well with the serverless paradigm, allowing for fine-grained cost control.
- Free tiers: Many platforms offer free tiers that provide a certain amount of free usage per month. These tiers are ideal for testing, development, and low-volume production workloads. For example, Google Cloud Functions offers a free tier that includes a certain number of function invocations, execution time, and compute time. Understanding the limits of the free tier is crucial to avoid unexpected charges.
- Reserved instances: While not strictly a serverless pricing model, some platforms offer reserved instances or committed use discounts, which can provide cost savings for predictable workloads. These options typically involve committing to a specific amount of resource usage for a defined period in exchange for a lower per-unit cost. This can be relevant if your inference workload has consistent traffic patterns.
To illustrate the impact of pricing, consider a scenario where you deploy a machine learning model for image classification. The model processes 10,000 images per day, with each inference taking 200 milliseconds and requiring 512 MB of memory. The pricing would vary depending on the chosen platform and its pricing structure. Regular monitoring and optimization of the inference process are essential to keep costs under control.
Key Features to Consider
Selecting a serverless platform involves evaluating several key features that directly impact the suitability for machine learning inference. These features include container support, GPU availability, and integration capabilities.
- Container Support: Container support, particularly with Docker, allows you to package your machine learning model and its dependencies into a portable container. This ensures consistency across different environments and simplifies deployment. Platforms like AWS Lambda support container images, enabling you to deploy complex models with their dependencies. This is particularly important for models with specific library requirements or custom runtimes.
- GPU Availability: For computationally intensive machine learning models, such as those used for deep learning, GPU acceleration is crucial for achieving acceptable performance. Not all serverless platforms offer GPU support. AWS Lambda provides GPU instances, enabling you to run models that require significant processing power. Azure Functions also offers GPU support, while Google Cloud Functions has limited GPU availability. The availability of GPUs significantly affects the inference latency and cost, especially for complex models.
- Integration Capabilities: The platform’s ability to integrate with other services is a significant consideration. For example, the ability to easily integrate with object storage (like S3 or Google Cloud Storage) for model storage, API gateways (like API Gateway or Azure API Management) for exposing inference endpoints, and message queues (like SQS or Pub/Sub) for asynchronous processing is essential. Seamless integration streamlines the development and deployment process.
- Cold Start Time: The time it takes for a serverless function to start up when it receives a request (the “cold start”) can impact the latency of your inference service. Platforms have varying cold start times, which can be crucial for applications requiring low latency. Factors influencing cold start times include the size of the function package, the programming language, and the platform’s underlying infrastructure.
- Maximum Execution Time and Memory Limits: Serverless platforms impose limits on the maximum execution time and memory that a function can use. These limits can be a constraint for machine learning inference, especially for large models or complex pre-processing tasks. It is essential to choose a platform that provides sufficient resources to meet the requirements of your model.
Preparing Your Machine Learning Model for Serverless Deployment
To effectively leverage serverless infrastructure for machine learning inference, meticulous preparation of the model is crucial. This involves optimizing the model for performance and resource utilization within the constraints of a serverless environment. Key steps include model serialization, packaging, and optimization techniques tailored to the serverless paradigm. The goal is to minimize latency, reduce cold start times, and efficiently utilize allocated resources, ultimately leading to cost-effective and scalable inference.
Model Serialization and Packaging for Serverless Environments
Model serialization is the process of converting a trained machine learning model into a format that can be stored, transmitted, and later reloaded for inference. Packaging ensures that the serialized model, along with its dependencies, is bundled in a manner suitable for deployment in a serverless function. This section details the methods and considerations for effective model serialization and packaging.Model serialization involves converting the model’s learned parameters, architecture, and any associated metadata into a persistent format.
Common serialization formats include:
- Pickle: Python’s built-in serialization library. Simple to use but not always the most efficient or secure, and can be version-dependent. Use with caution due to potential security vulnerabilities.
- Joblib: Optimized for Python and often preferred for scikit-learn models. Generally faster than Pickle for large numerical arrays.
- ONNX (Open Neural Network Exchange): An open standard for representing machine learning models. Allows interoperability between different frameworks (e.g., TensorFlow, PyTorch) and can be optimized for various hardware platforms.
- PMML (Predictive Model Markup Language): An XML-based standard for representing predictive models. Supports a wide range of models but can be less efficient than binary formats.
Packaging a model for serverless deployment typically involves the following steps:
- Serializing the Model: Choose an appropriate serialization format (e.g., ONNX, Joblib) based on the model type, framework, and performance requirements.
- Creating a Deployment Package: Bundle the serialized model file, any necessary libraries (e.g., NumPy, TensorFlow, PyTorch), and a prediction script into a deployment package. This package is typically a ZIP archive. The prediction script is the entry point for the serverless function and loads the model, preprocesses input data, makes predictions, and post-processes the output.
- Managing Dependencies: Ensure that all dependencies are included in the deployment package. Serverless platforms often have limitations on package size and the number of dependencies. Using a virtual environment (e.g., `venv`, `conda`) to manage dependencies is highly recommended.
- Uploading the Package: Upload the deployment package to the serverless platform’s storage (e.g., AWS S3, Google Cloud Storage). The serverless function is then configured to access the package and load the model during initialization.
Model Optimization Techniques for Serverless
Optimizing machine learning models is critical for serverless deployments, where resource constraints (CPU, memory, execution time) are more pronounced. Several techniques can be employed to reduce model size, improve inference speed, and minimize resource consumption.Model optimization techniques for serverless environments include:
- Quantization: Reducing the precision of the model’s weights and activations (e.g., from 32-bit floating-point to 8-bit integers). This reduces model size, memory usage, and can speed up inference, especially on hardware that supports quantized operations. Quantization-aware training is a technique where the model is trained with knowledge of the quantization process.
- Pruning: Removing less important weights or connections in the model. This reduces model size and can improve inference speed. Pruning techniques include structured pruning (removing entire filters or layers) and unstructured pruning (removing individual weights).
- Knowledge Distillation: Training a smaller, faster “student” model to mimic the behavior of a larger, more accurate “teacher” model. This allows for deploying a smaller model with potentially similar performance.
- Model Compression: Techniques that aim to reduce the model’s size without significantly affecting its performance. This includes techniques like weight sharing and matrix factorization.
- Hardware-Specific Optimization: Leveraging hardware acceleration (e.g., GPUs, TPUs) where available. Serverless platforms may offer support for specific hardware, allowing for faster inference.
Quantization can significantly reduce model size and improve inference speed. For example, a convolutional neural network (CNN) for image classification might have its weights and activations quantized from 32-bit floating-point to 8-bit integers. This can reduce the model’s memory footprint by a factor of four and, in some cases, speed up inference by a similar factor, particularly on hardware optimized for integer arithmetic.
However, the precision loss must be carefully managed to avoid a significant drop in accuracy.Pruning, such as removing redundant connections in a neural network, can also yield substantial benefits. Consider a deep learning model with a large number of parameters. Pruning removes those parameters that contribute the least to the model’s performance, reducing the model’s size and computational complexity. For instance, if a model contains 1 million parameters, pruning could eliminate 50% of the parameters, thereby decreasing model size and accelerating inference.
Step-by-Step Guide on Converting a Model for Serverless Deployment
Converting a machine learning model for serverless deployment involves several key steps, varying slightly depending on the framework used (e.g., TensorFlow, PyTorch). This section provides a general guide, with examples, to illustrate the process.The conversion process typically involves the following steps:
- Model Training and Saving: Train your model using your preferred framework (TensorFlow, PyTorch, etc.) and save the trained model.
- Model Conversion (if necessary): Convert the model to a suitable format for serverless deployment. This might involve converting a TensorFlow model to a SavedModel format or exporting a PyTorch model to ONNX.
- TensorFlow: TensorFlow models can be saved in the SavedModel format, which is the recommended format for production deployment. This format bundles the model’s architecture, weights, and other metadata. Example:
import tensorflow as tf
# Assuming 'model' is your trained TensorFlow model
model.save('path/to/saved_model')
- PyTorch: PyTorch models can be exported to ONNX, which is a standard format for model exchange. This allows the model to be used with different inference engines. Example:
import torch
# Assuming 'model' is your trained PyTorch model, and 'dummy_input' is an example input
torch.onnx.export(model, dummy_input, 'path/to/model.onnx')
- TensorFlow: TensorFlow models can be saved in the SavedModel format, which is the recommended format for production deployment. This format bundles the model’s architecture, weights, and other metadata. Example:
- Model Optimization: Apply optimization techniques like quantization and pruning to reduce model size and improve inference speed. Tools like TensorFlow Lite (for TensorFlow models) and ONNX Runtime (for ONNX models) provide capabilities for quantization and optimization.
- Quantization with TensorFlow Lite:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model('path/to/saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with open('path/to/model.tflite', 'wb') as f:
f.write(tflite_model)
- Quantization with ONNX Runtime: The ONNX Runtime provides tools to quantize ONNX models, often with support for post-training quantization.
- Quantization with TensorFlow Lite:
- Create a Prediction Script: Write a Python script that loads the model, preprocesses input data, makes predictions, and post-processes the output. This script will be the entry point for the serverless function.
- Create a Deployment Package: Bundle the model file (e.g., SavedModel, ONNX file, TFLite file), the prediction script, and any necessary dependencies into a ZIP archive.
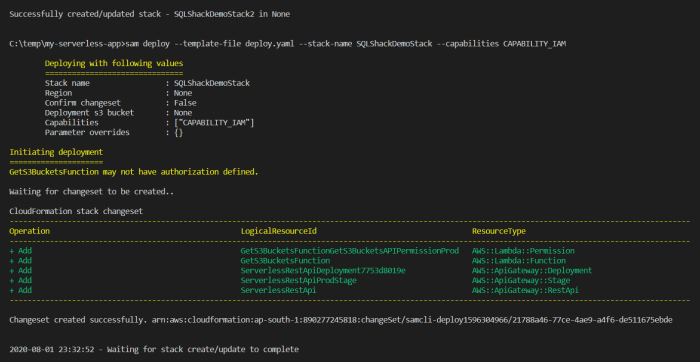
- Deploy to a Serverless Platform: Upload the deployment package to your chosen serverless platform (e.g., AWS Lambda, Google Cloud Functions, Azure Functions) and configure the function to run the prediction script.
This process is iterative, and testing and performance monitoring are crucial to ensure the model meets the desired performance and cost requirements within the serverless environment. Continuous integration and continuous deployment (CI/CD) pipelines can be used to automate the process of model training, optimization, packaging, and deployment.
Implementing Inference Endpoints
Creating a robust and scalable inference endpoint is crucial for deploying machine learning models in a serverless environment. This process involves several key steps, from defining the API structure to deploying and managing the function that performs the actual inference. This section Artikels the necessary procedures for establishing and configuring such an endpoint, providing code examples and practical considerations.
Steps for Creating an API Endpoint
The following steps are essential for establishing a functioning API endpoint capable of handling machine learning inference requests. These steps ensure that the model can be accessed and utilized effectively within a serverless architecture.
- Model Loading and Preparation: The machine learning model must be loaded into the serverless function’s environment. This involves importing the necessary libraries (e.g., TensorFlow, PyTorch, scikit-learn) and loading the pre-trained model from storage (e.g., cloud storage, local file system). The model should be prepared for inference, which might involve preprocessing the input data.
- API Gateway Configuration: An API gateway is configured to handle incoming requests. This includes defining the API endpoint (URL), the HTTP methods supported (e.g., POST), and any necessary authentication or authorization mechanisms. The API gateway acts as the entry point for all client requests.
- Function Creation and Deployment: A serverless function is created, which contains the inference logic. This function receives requests from the API gateway, preprocesses the input data, calls the loaded machine learning model for inference, and returns the model’s output. The function is deployed to the serverless platform.
- Request Handling and Input Validation: The serverless function should include code to validate incoming requests. This ensures that the input data conforms to the expected format and that the necessary parameters are provided. Validating input prevents errors and enhances the robustness of the endpoint.
- Inference Execution: Within the serverless function, the loaded model is executed using the preprocessed input data. The model’s output is then captured and prepared for the response.
- Response Formatting and Return: The inference output is formatted into a suitable response format (e.g., JSON). The function then returns the formatted response to the API gateway, which in turn sends it back to the client.
- Monitoring and Logging: Implementing monitoring and logging is critical. Metrics related to request latency, error rates, and resource utilization should be tracked. Logs should be collected to facilitate debugging and performance analysis.
Python Code for Model Loading and Inference
The following Python code snippets demonstrate how to load a pre-trained model and perform inference within a serverless function. These examples assume a pre-trained model is available in a cloud storage location and uses the `requests` library for handling HTTP requests.“`pythonimport jsonimport osimport requestsimport tensorflow as tf # or your preferred ML framework# Cloud Storage URL for the model (replace with your actual URL)MODEL_URL = os.environ.get(‘MODEL_URL’, ‘https://example.com/path/to/your/model.h5’)# Global variable to hold the modelmodel = Nonedef load_model(): “””Loads the pre-trained model from cloud storage.””” global model try: # Download the model from cloud storage (e.g., using requests) response = requests.get(MODEL_URL, stream=True) response.raise_for_status() # Raise an exception for bad status codes # Save the model temporarily (adjust path as needed) model_path = ‘/tmp/model.h5’ # Or a suitable temporary directory with open(model_path, ‘wb’) as f: for chunk in response.iter_content(chunk_size=8192): if chunk: f.write(chunk) # Load the model using TensorFlow (or your framework) model = tf.keras.models.load_model(model_path) # Modify for other frameworks print(“Model loaded successfully.”) except requests.exceptions.RequestException as e: print(f”Error downloading model: e”) raise # Re-raise the exception to signal failure except Exception as e: print(f”Error loading model: e”) raise # Re-raise the exception to signal failuredef preprocess_input(data): “””Preprocesses the input data for the model.””” try: # Assuming the input is a JSON payload input_data = json.loads(data) # Example: Extract the relevant features (replace with your logic) features = input_data.get(‘features’) if features is None: raise ValueError(“Missing ‘features’ in the input data.”) # Convert to numpy array (adjust shape as needed) import numpy as np features_array = np.array(features).reshape(1, -1) # Example: reshape for a single sample return features_array except json.JSONDecodeError as e: raise ValueError(f”Invalid JSON format: e”) except ValueError as e: raise ValueError(f”Input preprocessing error: e”)def predict(event, context): “””Handles the inference request.””” global model try: if model is None: load_model() # Get the input data from the event (e.g., API Gateway event) data = event.get(‘body’) if data is None: return ‘statusCode’: 400, ‘body’: json.dumps(‘message’: ‘Missing request body’) # Preprocess the input data try: preprocessed_input = preprocess_input(data) except ValueError as e: return ‘statusCode’: 400, ‘body’: json.dumps(‘message’: f’Preprocessing error: str(e)’) # Perform inference try: predictions = model.predict(preprocessed_input).tolist() # Convert to list for JSON serialization except Exception as e: return ‘statusCode’: 500, ‘body’: json.dumps(‘message’: f’Inference error: str(e)’) # Prepare the response response = ‘statusCode’: 200, ‘body’: json.dumps(‘predictions’: predictions) return response except Exception as e: # Catch any other errors print(f”Unexpected error: e”) return ‘statusCode’: 500, ‘body’: json.dumps(‘message’: ‘Internal server error’) “`This code demonstrates the core components of a serverless inference function: loading the model, preprocessing the input, making predictions, and formatting the output.
Note that error handling is included to make the function more robust. The `MODEL_URL` is set using an environment variable to make it configurable.
API Gateway Integration
API gateways play a critical role in routing requests to serverless functions. The following example illustrates how to configure an API gateway to handle incoming requests and route them to the inference function. This example uses a conceptual illustration. Actual configuration steps will vary based on the specific cloud provider (e.g., AWS API Gateway, Google Cloud API Gateway, Azure API Management).
1. API Creation
An API is created within the API gateway service. The API acts as a container for the resources (endpoints) that will be exposed.
2. Resource Creation
A resource (e.g., `/predict`) is created within the API. This represents the endpoint that clients will use to submit inference requests.
3. Method Configuration
A method (e.g., `POST`) is configured for the resource. This specifies the HTTP method that clients must use to interact with the endpoint.
4. Integration with Serverless Function
The method is integrated with the serverless function. This involves specifying the function’s ARN (Amazon Resource Name), or equivalent, which allows the API gateway to invoke the function when a request is received.
5. Request Mapping (Optional)
Request mapping may be configured to transform the incoming request before it is sent to the function. This can include mapping the request body, headers, or query parameters.
6. Response Mapping (Optional)
Response mapping may be configured to transform the function’s response before it is returned to the client. This can include mapping the response body, headers, or status code.
7. Deployment
The API is deployed, making it accessible to clients. This process generates a unique API endpoint URL that clients can use to submit requests.An illustration of an API Gateway handling requests and routing them to the serverless function.* Client: Sends a `POST` request to the API Gateway endpoint. The request includes the input data for the machine learning model.* API Gateway: Receives the request.* API Gateway: Routes the request to the serverless function (e.g., via an ARN).* Serverless Function: Receives the request.
It loads the model, preprocesses the input data, performs inference, and formats the output.* Serverless Function: Returns the response to the API Gateway.* API Gateway: Returns the response to the client.The API gateway manages authentication, authorization, rate limiting, and other aspects of the API, allowing developers to focus on the core inference logic within the serverless function.
Input Data Handling and Preprocessing

Serverless functions, designed for event-driven execution, require robust mechanisms for handling diverse input data formats and preprocessing them effectively. This is crucial for ensuring the model receives data in the expected format and for optimizing performance. Data preprocessing is a vital step that transforms raw input data into a suitable format for the machine learning model, enhancing its accuracy and efficiency.
Handling Different Input Data Formats
Serverless functions must accommodate a variety of input data formats to be versatile. These formats often include JSON, images, and audio. The ability to parse and process these different data types is fundamental for integrating serverless functions with various data sources and applications.
- JSON Data Handling: JSON (JavaScript Object Notation) is a prevalent data format for web applications and APIs. Serverless functions commonly receive data in JSON format, necessitating parsing and data extraction.
- Example: Consider a serverless function triggered by an API Gateway. The function receives a JSON payload containing user profile data. The function would use a library like `json` (Python) or `JSON.parse()` (JavaScript) to parse the JSON and access specific fields like `name`, `age`, and `email`. This parsed data can then be passed to the machine learning model.
- Image Data Handling: Processing images often involves reading image files, decoding the image data, and potentially resizing or transforming the image pixels. This is crucial for computer vision tasks.
- Example: A serverless function receives an image uploaded to an object storage service like AWS S3. The function uses libraries like `PIL` (Python) or `sharp` (Node.js) to open the image, perform operations like resizing to a specific dimension (e.g., 224×224 pixels, commonly used in models like ResNet), and convert the image data into a numerical representation (e.g., a NumPy array) suitable for the machine learning model.
- Audio Data Handling: Handling audio data includes decoding audio files (e.g., WAV, MP3), extracting audio features, and preparing the data for the model.
- Example: A serverless function receives an audio file. The function uses a library like `librosa` (Python) or `node-wav` (Node.js) to decode the audio file, extract features like Mel-Frequency Cepstral Coefficients (MFCCs), and convert the audio data into a numerical representation suitable for the machine learning model.
Code Examples for Preprocessing Data
Preprocessing code examples demonstrate how to manipulate the input data to make it suitable for the machine learning model. The specific preprocessing steps depend on the data type and the model’s requirements. These examples are designed to illustrate common preprocessing tasks.
- JSON Data Preprocessing (Python):
- Example: Assume a serverless function receives a JSON payload containing text data. The function uses Natural Language Toolkit (NLTK) for preprocessing:
import json import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize import re def preprocess_text(text): text = re.sub(r'[^a-zA-Z\s]', '', text, re.I|re.A) # Remove special characters text = text.lower() stop_words = set(stopwords.words('english')) word_tokens = word_tokenize(text) filtered_sentence = [w for w in word_tokens if not w in stop_words] return " ".join(filtered_sentence) def handler(event, context): try: body = json.loads(event['body']) text = body['text'] processed_text = preprocess_text(text) return 'statusCode': 200, 'body': json.dumps('processed_text': processed_text) except Exception as e: return 'statusCode': 500, 'body': json.dumps('error': str(e))- This example removes special characters, converts text to lowercase, removes stop words, and tokenizes the text.
- Image Data Preprocessing (Python):
- Example: A serverless function receives an image from S3, resizes it, and converts it to a NumPy array.
from PIL import Image import io import numpy as np import boto3 s3 = boto3.client('s3') def preprocess_image(image_bytes): img = Image.open(io.BytesIO(image_bytes)) img = img.resize((224, 224)) # Resizing the image img_array = np.array(img) return img_array.astype(np.float32) / 255.0 # Normalization def handler(event, context): try: bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] obj = s3.get_object(Bucket=bucket, Key=key) image_bytes = obj['Body'].read() processed_image = preprocess_image(image_bytes) return 'statusCode': 200, 'body': json.dumps('processed_image_shape': processed_image.shape) except Exception as e: return 'statusCode': 500, 'body': json.dumps('error': str(e))- This example retrieves the image from S3, opens it using Pillow, resizes the image to 224×224 pixels, and converts the pixel data into a normalized NumPy array.
- Audio Data Preprocessing (Python):
- Example: A serverless function receives an audio file, decodes it, and extracts MFCCs.
import librosa import numpy as np import boto3 import io s3 = boto3.client('s3') def preprocess_audio(audio_bytes, sr=22050): try: audio, sr = librosa.load(io.BytesIO(audio_bytes), sr=sr) mfccs = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=13) return mfccs except Exception as e: print(f"Error processing audio: e") return None def handler(event, context): try: bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] obj = s3.get_object(Bucket=bucket, Key=key) audio_bytes = obj['Body'].read() mfccs = preprocess_audio(audio_bytes) if mfccs is not None: return 'statusCode': 200, 'body': json.dumps('mfccs_shape': mfccs.shape) else: return 'statusCode': 500, 'body': json.dumps('error': 'Audio processing failed') except Exception as e: return 'statusCode': 500, 'body': json.dumps('error': str(e))- This example uses `librosa` to load the audio, extract MFCCs, and return the MFCC features.
Strategies for Handling Large Input Files or Data Streams
Handling large input files or continuous data streams presents unique challenges in a serverless environment. The strategies employed must address memory constraints, execution time limits, and the need for efficient data processing.
- Chunking and Streaming: For large files, process the data in chunks. Read the file in segments, process each segment, and pass the processed data to the model.
- Example: When processing a large video file, read the video frame by frame. Perform object detection on each frame using the model.
- Asynchronous Processing: Use asynchronous task queues to handle data streams or large files. This prevents blocking the main function execution.
- Example: When processing a large dataset, send each data item to a queue (e.g., AWS SQS). The serverless function consumes items from the queue and processes them asynchronously.
- Object Storage Integration: Utilize object storage services (e.g., AWS S3, Google Cloud Storage) for storing large files and retrieving them in chunks.
- Example: Upload a large dataset to an S3 bucket. The serverless function can be triggered by an S3 event (e.g., file upload) and process the file in chunks, avoiding memory limitations.
- Data Compression: Compress the data before passing it to the serverless function. This reduces the data size and improves processing speed.
- Example: Compress a large text file using gzip before uploading it to S3. The serverless function can decompress the file and process the text data.
- Optimizing Model Input: Reduce the size of the input data by feature selection or dimensionality reduction.
- Example: Use Principal Component Analysis (PCA) to reduce the number of features in a dataset before passing it to the model.
Output Processing and Post-processing
Post-processing is a crucial step in serverless machine learning inference, transforming raw model outputs into a usable and interpretable format. This step significantly enhances the practical value of the inference results, making them easier to integrate into applications and workflows. Without effective post-processing, the raw output from a model, which can often be numerical values or probability distributions, would be difficult for end-users or downstream systems to understand and utilize effectively.
Importance of Post-processing for Usability
The primary goal of post-processing is to convert the model’s raw output into a format that is easily understood and utilized. This involves several key considerations:
- Data Transformation: Raw outputs may require scaling, normalization, or other mathematical transformations to be meaningful. For instance, if a model predicts a bounding box, the raw output might be coordinates relative to the image; post-processing would convert these to pixel coordinates, making them directly usable.
- Contextualization: Adding context to the output can dramatically increase its value. For example, a sentiment analysis model might output a probability score for positive sentiment. Post-processing could translate this score into a human-readable label (e.g., “Positive,” “Negative,” “Neutral”) and potentially provide an explanation or confidence level.
- Error Handling: Post-processing can include checks for potential errors or edge cases in the model’s output. If a prediction is outside a reasonable range, the post-processing step can handle it gracefully, perhaps by returning a default value or triggering an alert.
- Format Conversion: The final format should align with the application’s needs. This can include converting the output into JSON, text, or other formats, as well as generating images or other visual representations of the data.
Comparison of Output Formats
The choice of output format depends heavily on the intended use case of the inference results. Different formats offer varying advantages in terms of readability, ease of integration, and information density.
- JSON (JavaScript Object Notation): JSON is a widely used, human-readable format that is well-suited for structured data. It is easy to parse and integrate into various applications and programming languages. For example, a model predicting object detections might return a JSON array of objects, each with bounding box coordinates, class labels, and confidence scores.
- Text: Plain text can be a simple and effective format for tasks like text classification or sentiment analysis. The output might be a single word or a short phrase, making it easy to understand and use. For example, a sentiment analysis model could return “Positive,” “Negative,” or “Neutral.”
- Images: For computer vision tasks, the output can be an image with annotations. This requires post-processing to draw bounding boxes, segment objects, or overlay other visualizations on the original image.
- CSV (Comma-Separated Values): CSV is a common format for tabular data, suitable for applications like data analysis and reporting. The output might include multiple predictions, each represented as a row in the CSV file.
- Binary Formats: Certain applications may require binary formats such as protocol buffers or other specialized formats for efficiency and performance. This is particularly relevant for high-volume, low-latency applications.
Examples of Formatting and Returning Inference Results
The following examples demonstrate how to format and return inference results from a serverless function using Python.
Example 1: Sentiment Analysis with JSON Output
Assume a sentiment analysis model predicts the sentiment of a given text. The model’s raw output is a probability score for each sentiment class (e.g., positive, negative, neutral). Post-processing transforms these scores into a JSON object with a human-readable sentiment label and a confidence score.
import jsondef sentiment_analysis_handler(event, context): # Assuming the model predicts sentiment scores raw_output = get_model_prediction(event['text']) # Simplified model call # Post-processing sentiment_label = determine_sentiment(raw_output) confidence = raw_output[sentiment_label] # Create the output output = "sentiment": sentiment_label, "confidence": confidence, "input_text": event['text'] return 'statusCode': 200, 'headers': 'Content-Type': 'application/json' , 'body': json.dumps(output) def determine_sentiment(scores): # Determine the sentiment label based on scores if scores['positive'] > 0.7: return "Positive" elif scores['negative'] > 0.7: return "Negative" else: return "Neutral"
In this example, the `determine_sentiment` function converts the raw scores into a label.
The function then returns a JSON response, including the input text for context.
Example 2: Object Detection with Image Annotations
Consider a computer vision model that performs object detection. The model’s output includes bounding box coordinates, class labels, and confidence scores for each detected object. Post-processing involves drawing these bounding boxes on the original image and returning the annotated image. This requires the use of libraries like OpenCV or Pillow.
import jsonimport cv2import numpy as npdef object_detection_handler(event, context): # Assume the event contains the image data and model predictions image_data = base64.b64decode(event['image_base64']) image = cv2.imdecode(np.frombuffer(image_data, np.uint8), cv2.IMREAD_COLOR) predictions = get_model_predictions(image) # Simplified model call # Post-processing: Draw bounding boxes on the image annotated_image = draw_boxes(image, predictions) # Convert the annotated image to base64 for the response annotated_image_bytes = cv2.imencode('.jpg', annotated_image)[1].tobytes() annotated_image_base64 = base64.b64encode(annotated_image_bytes).decode('utf-8') return 'statusCode': 200, 'headers': 'Content-Type': 'application/json' , 'body': json.dumps( 'annotated_image_base64': annotated_image_base64, 'predictions': predictions ) def draw_boxes(image, predictions): # Iterate over the predictions and draw bounding boxes for prediction in predictions: box = prediction['box'] class_name = prediction['class'] confidence = prediction['confidence'] x1, y1, x2, y2 = map(int, box) # Assuming box format is [x1, y1, x2, y2] cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2) # Green boxes cv2.putText(image, f'class_name: confidence:.2f', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2) return image In this example, the `draw_boxes` function takes the image and predictions, draws the bounding boxes, and then encodes the annotated image as a base64 string for transmission in the JSON response.
The response also includes the raw prediction data for additional context.
Monitoring and Logging
Effective monitoring and logging are crucial for maintaining the health, performance, and reliability of serverless machine learning inference endpoints. They provide insights into system behavior, enabling proactive identification and resolution of issues, performance optimization, and informed decision-making. This section details how to set up monitoring and logging for your serverless inference endpoints, focusing on collecting key metrics and designing a performance dashboard.
Setting Up Monitoring and Logging Infrastructure
The first step involves integrating logging and monitoring tools with the serverless platform. This typically involves configuring the platform’s built-in logging and monitoring services, or integrating with third-party solutions.
- Platform-Specific Logging: Most serverless platforms (e.g., AWS Lambda, Google Cloud Functions, Azure Functions) provide native logging capabilities. These services automatically capture logs from function executions, including standard output, standard error, and custom logs. Configure the function’s execution environment to send logs to a centralized logging service, such as CloudWatch Logs (AWS), Cloud Logging (Google Cloud), or Azure Monitor Logs (Azure).
- Custom Logging: Implement custom logging within the inference endpoint code to capture application-specific events and data. This allows you to track the flow of requests, the performance of specific code segments, and the values of key variables. Use a structured logging format (e.g., JSON) to facilitate parsing and analysis.
- Metrics Collection: Serverless platforms provide metrics for monitoring resource utilization, such as memory usage, execution time, and invocation counts. These metrics are essential for understanding the overall performance of the inference endpoints. Additionally, implement custom metrics to track model-specific performance indicators, such as inference latency and error rates.
- Third-Party Integrations: Consider integrating with third-party logging and monitoring solutions, such as Datadog, New Relic, or Prometheus, for advanced features like distributed tracing, complex alerting, and custom dashboards. These services often provide more sophisticated analysis capabilities and integrations with other tools in the development and operations pipelines.
Collecting Key Metrics
Collecting relevant metrics is fundamental to understanding the performance of serverless inference endpoints. Focus on metrics that provide insights into the system’s health, performance, and potential bottlenecks.
- Latency: Measure the time taken for the inference endpoint to process a request and return a response. Latency is a critical performance indicator, and high latency can significantly impact the user experience.
- Measure latency at the API gateway level (if applicable) to capture the end-to-end response time.
- Measure latency within the inference endpoint code to identify performance bottlenecks in the model loading, preprocessing, inference, or post-processing steps.
- Error Rates: Track the frequency of errors, such as failed requests, exceptions, and model prediction errors. High error rates indicate potential issues with the model, the infrastructure, or the input data.
- Monitor HTTP status codes returned by the API gateway to identify client-side and server-side errors.
- Log exceptions and error messages within the inference endpoint code to provide detailed information about the root causes of errors.
- Invocation Counts: Track the number of times the inference endpoint is invoked. This metric provides insights into the traffic volume and the overall usage of the endpoint.
- Monitor the number of requests received by the API gateway.
- Track the number of function invocations in the serverless platform.
- Resource Utilization: Monitor the resource utilization of the serverless functions, such as memory usage, CPU usage, and network I/O. This information helps identify resource bottlenecks and optimize the function’s configuration.
- Use the platform’s built-in metrics to monitor resource utilization.
- Configure alerts to notify you when resource utilization exceeds predefined thresholds.
- Model-Specific Metrics: Track metrics specific to the machine learning model, such as prediction accuracy, precision, recall, and F1-score. This information helps evaluate the model’s performance and identify potential degradation over time.
- Calculate and log model-specific metrics within the inference endpoint code.
- Use these metrics to track model performance and identify potential issues.
Designing a Performance Dashboard
A well-designed performance dashboard provides a centralized view of the system’s health and performance. It allows for quick identification of issues and informed decision-making.
- Metric Selection: Choose the most relevant metrics to display on the dashboard, including latency, error rates, invocation counts, and resource utilization. Also, include model-specific metrics if they are relevant.
- Visualization Techniques: Use appropriate visualization techniques to represent the metrics effectively.
- Use line charts to visualize trends over time.
- Use bar charts to compare performance across different time periods or configurations.
- Use gauges to display the current values of key metrics.
- Use tables to present detailed information about individual requests or errors.
- Dashboard Layout: Organize the dashboard logically, grouping related metrics together.
- Include a summary section at the top of the dashboard to display the most important metrics, such as overall latency, error rates, and invocation counts.
- Include sections for specific components of the system, such as the API gateway, the serverless functions, and the machine learning model.
- Alerting and Notifications: Configure alerts to notify you when key metrics exceed predefined thresholds.
- Set up alerts for high latency, high error rates, and excessive resource utilization.
- Configure notifications to be sent to the appropriate channels, such as email, Slack, or PagerDuty.
- Example Dashboard (Illustrative): Consider a dashboard layout, with the following example components. Note that these are illustrative, and the specific metrics and visualizations will vary depending on the specific application and needs.
Top Section (Summary):- A large gauge showing the current average latency (e.g., in milliseconds).
- A large gauge showing the current error rate (e.g., percentage of failed requests).
- A line chart showing the number of invocations over the past hour.
API Gateway Section:
- A line chart showing the latency of requests received by the API gateway over time.
- A bar chart showing the distribution of HTTP status codes returned by the API gateway (e.g., 200 OK, 400 Bad Request, 500 Internal Server Error).
Serverless Function Section:
- A line chart showing the average execution time of the serverless function over time.
- A line chart showing the memory usage of the serverless function over time.
- A line chart showing the CPU utilization of the serverless function over time.
Model Performance Section:
- A line chart showing the model’s accuracy over time (if applicable).
- A line chart showing the model’s precision and recall over time (if applicable).
Alerts Section:
- A table listing active alerts and their status.
This illustrative dashboard is designed to provide a comprehensive view of the system’s performance. The choice of metrics, visualizations, and layout will depend on the specific requirements of the application.
Scaling and Optimization Strategies

Serverless machine learning inference presents unique opportunities and challenges concerning performance and scalability. Efficiently managing resource allocation and function execution is crucial for delivering low-latency predictions and cost-effective operations. This section Artikels key strategies for optimizing serverless function performance, ensuring automated scaling, and leveraging caching mechanisms to handle varying workloads.
Cold Start Reduction
Cold starts, the initial delay experienced when a serverless function is invoked after a period of inactivity, can significantly impact inference latency. Reducing cold start times is paramount for maintaining responsiveness.
- Provisioned Concurrency: This approach involves pre-warming function instances to maintain a pool of ready-to-serve resources. Provisioned concurrency helps to eliminate cold starts by ensuring that function instances are available to handle incoming requests immediately. For example, if a model predicts a sudden increase in traffic, provisioned concurrency can pre-allocate instances to accommodate the load, avoiding the latency associated with starting new instances.
Cloud providers, such as AWS Lambda, offer features like provisioned concurrency, allowing developers to specify the number of concurrent instances to be kept warm. The cost of provisioned concurrency is higher than on-demand invocation, but the performance gains can be substantial.
- Optimized Code Packaging: Reducing the size of the deployment package can decrease cold start times. This involves removing unnecessary dependencies and using techniques like code minification and tree-shaking to eliminate unused code. For instance, using a slimmed-down version of a deep learning framework, such as TensorFlow Lite or ONNX Runtime, can reduce the package size and speed up the loading process.
- Efficient Initialization: Minimize the amount of work performed during function initialization. This means deferring resource-intensive operations, such as model loading, until the first invocation. Consider lazy loading models, where the model is loaded only when the function receives its first request.
- Container Image Optimization: Using container images can provide greater control over the function’s runtime environment. Optimize the container image by using a minimal base image, such as Alpine Linux, and carefully selecting the dependencies.
Automated Scaling Strategies
Serverless platforms automatically scale functions based on incoming traffic, but fine-tuning the scaling behavior can improve performance and cost efficiency.
- Concurrency Limits: Set appropriate concurrency limits for functions to prevent overloading resources. This can be achieved by configuring the maximum number of concurrent executions allowed for a function. Setting concurrency limits helps prevent a single function from consuming all available resources and causing performance degradation or errors.
- Traffic-Based Scaling: Configure auto-scaling policies that adjust the number of function instances based on metrics such as the number of incoming requests, the average execution time, or the number of errors. For example, the AWS Lambda service uses CloudWatch metrics to monitor function performance. When the average execution time exceeds a predefined threshold, the auto-scaling policy can automatically increase the number of function instances.
- Queue-Based Scaling: Integrate serverless functions with message queues, such as Amazon SQS or Google Cloud Pub/Sub. The queue can buffer incoming requests, and the serverless functions can scale up to process the messages in the queue. This approach is particularly useful for handling bursts of requests or asynchronous processing. The queue’s length can be used to trigger scaling events, ensuring the function instances scale up to meet the demand.
- Predictive Scaling: Use machine learning models to predict future traffic patterns and proactively scale the function instances. This can involve analyzing historical traffic data and using time-series forecasting models to anticipate demand. Predictive scaling can help to avoid cold starts and ensure that the function is ready to handle incoming requests before they arrive.
Caching for Improved Performance
Caching can significantly improve the performance of frequently accessed results, reducing the load on the serverless functions and lowering latency.
- Caching Frameworks: Employ caching frameworks such as Redis or Memcached to store and retrieve frequently accessed results. Implement a caching layer in front of the serverless function. When a request arrives, the function first checks the cache. If the result is found in the cache, it’s returned directly. Otherwise, the function executes the inference, stores the result in the cache, and then returns it.
- Cache Key Design: Design effective cache keys to ensure that the correct results are retrieved from the cache. The cache key should uniquely identify the input data or the parameters used for the inference. Consider using a combination of input data, model version, and any relevant parameters.
- Cache Invalidation: Implement strategies for invalidating the cache when the underlying data or model changes. This can involve setting time-to-live (TTL) values for cached items or using event-driven mechanisms to invalidate the cache when the data or model is updated. Regularly invalidating the cache ensures that the function uses the latest version of the model or data.
- Content Delivery Networks (CDNs): For static or less frequently changing results, consider using CDNs. CDNs store cached copies of the results at multiple locations around the world, reducing latency for users in different geographic regions.
Security Considerations
Securing serverless machine learning inference endpoints is paramount to protect both the deployed models and the sensitive data they process. Neglecting security can lead to unauthorized access, data breaches, and potential model manipulation, resulting in significant financial and reputational damage. Robust security measures are essential throughout the entire inference pipeline, from authentication and authorization to data encryption and model protection.
Security Best Practices for Serverless Machine Learning Inference
Implementing a multi-layered security approach is crucial to safeguard serverless ML inference deployments. This involves securing the infrastructure, the model, and the data throughout its lifecycle.
- Authentication and Authorization: Enforce strict access control mechanisms to verify the identity of users and services accessing the inference endpoints. Implement robust authentication methods like API keys, tokens, or identity providers (e.g., OAuth 2.0, OpenID Connect). Define granular authorization policies to restrict access to specific resources and actions based on user roles and permissions.
- Data Encryption: Employ encryption at rest and in transit to protect sensitive data. Use encryption keys managed by a secure key management service (KMS) to encrypt model artifacts, input data, and output predictions. Ensure data is encrypted during transmission between clients and inference endpoints using TLS/SSL.
- Input Validation and Sanitization: Validate and sanitize all incoming data to prevent malicious attacks such as SQL injection, cross-site scripting (XSS), and other input-based vulnerabilities. Implement schema validation to ensure data conforms to the expected format and data types.
- Network Security: Configure network security controls, such as firewalls and virtual private clouds (VPCs), to restrict network access to the inference endpoints. Limit access to only authorized sources and services. Regularly monitor network traffic for suspicious activity.
- Regular Security Audits and Penetration Testing: Conduct regular security audits and penetration testing to identify and address potential vulnerabilities. Employ automated security scanning tools to detect common security flaws. Regularly update dependencies and libraries to patch known security vulnerabilities.
- Model Monitoring and Anomaly Detection: Implement monitoring and logging to detect suspicious activities and unauthorized access attempts. Monitor model performance metrics, such as prediction accuracy and latency, to identify potential model manipulation or degradation. Employ anomaly detection techniques to identify unusual patterns in input data or prediction outputs.
- Least Privilege Principle: Grant only the necessary permissions to the serverless functions and other resources. Avoid granting excessive permissions that could be exploited by attackers.
- Secret Management: Securely store and manage sensitive information, such as API keys, database credentials, and encryption keys. Use a dedicated secrets management service to store and rotate secrets securely.
Authentication and Authorization Methods for API Endpoints
Choosing the right authentication and authorization methods is crucial for controlling access to inference endpoints. The selection depends on the specific requirements of the application, including the user base, security needs, and compliance requirements.
- API Keys: API keys are a simple method for authenticating clients. Clients include the API key in the request headers. This method is easy to implement but less secure than other methods because API keys can be compromised.
- Example: A mobile application uses an API key to access a serverless inference endpoint for image recognition. The application sends the API key in the `X-API-Key` header of each request.
- JSON Web Tokens (JWT): JWTs are a more secure and flexible authentication method. Clients authenticate with an identity provider (IdP) and receive a JWT. The JWT is then included in the request headers. The serverless function verifies the JWT’s signature to authenticate the client.
- Example: A web application uses a JWT to access a serverless inference endpoint for sentiment analysis.
The application authenticates with a user’s credentials and receives a JWT from an authentication service. The application then includes the JWT in the `Authorization` header of each request.
- Example: A web application uses a JWT to access a serverless inference endpoint for sentiment analysis.
- OAuth 2.0: OAuth 2.0 is an industry-standard protocol for delegated authorization. Clients obtain an access token from an authorization server (e.g., Google, Facebook) and include the access token in the request headers. The serverless function verifies the access token to authenticate the client and authorize access to resources.
- Example: An application uses OAuth 2.0 to allow users to access a serverless inference endpoint for natural language processing.
The application redirects users to a third-party authorization server, where they grant the application permission to access their data. The application then uses the access token to access the inference endpoint.
- Example: An application uses OAuth 2.0 to allow users to access a serverless inference endpoint for natural language processing.
- Mutual TLS (mTLS): mTLS provides mutual authentication between the client and the server. Both the client and the server present certificates to each other for verification. This method offers strong security but requires certificate management.
- Example: A financial institution uses mTLS to secure access to a serverless inference endpoint for fraud detection. Both the client application and the inference endpoint are configured with digital certificates, ensuring that only authorized applications can access the service.
Protecting Your Model from Unauthorized Access
Protecting the model itself from unauthorized access is as critical as securing the API endpoints. Unauthorized access can lead to model theft, manipulation, or reverse engineering, potentially resulting in intellectual property theft, competitive disadvantage, and security breaches.
- Model Encryption: Encrypt the model file at rest using a key managed by a secure KMS. This prevents unauthorized access to the model file even if the storage location is compromised.
- Access Control for Model Storage: Restrict access to the model file in the storage location (e.g., object storage) using appropriate IAM policies. Grant access only to the serverless function and authorized personnel.
- Rate Limiting and Throttling: Implement rate limiting and throttling to prevent excessive requests and potential denial-of-service (DoS) attacks. This helps to mitigate the impact of unauthorized access attempts.
- Input Data Filtering: Validate and filter input data to prevent malicious inputs that could be used to manipulate the model or extract information. Implement input validation techniques such as regular expressions and schema validation.
- Model Obfuscation: Obfuscate the model code to make it more difficult to reverse engineer. Techniques include code minification, variable renaming, and control flow obfuscation. However, note that obfuscation is not a foolproof security measure and should be used in conjunction with other security practices.
- Watermarking: Embed a unique watermark into the model to detect unauthorized use or modification. Watermarks can be used to identify the origin of the model and track its usage.
For example, a company develops a machine learning model for predicting customer churn. To protect the model from unauthorized access, the company can encrypt the model file, restrict access to the storage location using IAM policies, and implement rate limiting to prevent excessive requests. The company can also use input data filtering to prevent malicious inputs and embed a unique watermark into the model to track its usage.
Conclusive Thoughts

In conclusion, the integration of serverless technology with machine learning inference has opened new avenues for creating dynamic and efficient applications. By embracing serverless architectures, developers can streamline the deployment process, reduce operational costs, and achieve unparalleled scalability. From model preparation and endpoint implementation to monitoring and security considerations, the journey toward serverless inference offers a powerful and transformative approach to building intelligent systems.
The future of machine learning is undoubtedly intertwined with the flexibility and agility that serverless computing provides, paving the way for innovative solutions across diverse industries.
Commonly Asked Questions
What are the primary cost advantages of using serverless for machine learning inference?
Serverless platforms typically offer a pay-per-use pricing model, where you are charged only for the compute time consumed during model inference. This eliminates the need for pre-provisioned infrastructure and reduces costs, especially for applications with fluctuating traffic patterns or infrequent usage. Furthermore, auto-scaling capabilities ensure resources are only allocated when needed, optimizing cost efficiency.
How does serverless address the challenge of model deployment and updates?
Serverless platforms simplify model deployment by abstracting away infrastructure management. You can upload your model and associated code directly to the platform, which handles the scaling, provisioning, and versioning. Updates are also straightforward; you can upload a new version of your model without disrupting existing inference services, facilitating rapid iteration and improvement.
What are the common limitations of serverless for machine learning inference?
One limitation is the potential for cold starts, where the function takes longer to initialize if it hasn’t been used recently. This can impact latency. Additionally, serverless platforms may have limitations on execution time, memory, and the size of deployment packages. Careful model optimization and platform selection are crucial to mitigate these constraints.
How can I optimize my machine learning model for serverless deployment?
Model optimization techniques such as quantization (reducing the precision of model weights), pruning (removing less important weights), and model compression can significantly reduce the size of the model and improve inference speed. Choosing a framework that supports optimized model formats for the target serverless platform is also beneficial.
What security measures should be implemented for serverless machine learning inference endpoints?
Implement robust authentication and authorization mechanisms to control access to your inference endpoints. Use API gateways to manage and secure API traffic. Employ encryption to protect data in transit and at rest. Regularly audit your code and infrastructure for vulnerabilities, and adhere to security best practices recommended by your chosen serverless platform.